Для работы с графическими TFT-дисплеями (например, ITDB02-3.2S) существует замечательная библиотека UTFT (которая совсем недавно обрела новую версию, которая существенно быстрее предыдущей).
И все в этой библиотеке замечательно - доступны необходимые графические примитивы (прямоугольники, круги, линии, точки, прямоугольники с закругленными углами и т.п.) и есть возможность использовать различные шрифты, но все шрифты, к сожалению, содержат символы латинского алфавита и стандартные символы.
Во многих случаях этого вполне достаточно (большинство тех, кто увлекается "ардуино" - владеют английским и надписи на английском воспринимаются ими вполне адекватно), но когда устройство переходит из статуса "прототип" (для разработчика) и получает некоторое движение в сторону "продакшн" (уже для реального использования) - надписи на русском языке становятся более предпочтительными.
Как оказалось, "русифицировать" данную библиотеку оказалось относительно несложно ("относительно" - только из-за кропотливости данной работы - требуется фактически попиксельно отрисовать каждый недостающий символ).
Результат русификации можно увидеть на следующем изображении (фотография с экрана TFT):

Где в первой строке объявлен массив SmallFonts, указана его длинна (1144). В следующей строке видим 4 байта:
Безусловно, это все можно делать ровно по той схеме, что описано, но это как-то совершенно не интересно - работа абсолютно рутинная и требует много "ручных" действий.
Чтобы как-то эту ситуацию улучшить, воспользуемся замечательным инструментом: Microsoft Excel (или бесплатным аналогом из OpenOffice).
Автоматизируем следующее:

Тестовый скетч выводит все символы двух шрифтов, которые упоминаются в этом посте: SmallFont и SmallSymbolFont:

На этом первая часть русификации библиотеки завершена.
Следите за обновлениями, продолжение следует...
И все в этой библиотеке замечательно - доступны необходимые графические примитивы (прямоугольники, круги, линии, точки, прямоугольники с закругленными углами и т.п.) и есть возможность использовать различные шрифты, но все шрифты, к сожалению, содержат символы латинского алфавита и стандартные символы.
Во многих случаях этого вполне достаточно (большинство тех, кто увлекается "ардуино" - владеют английским и надписи на английском воспринимаются ими вполне адекватно), но когда устройство переходит из статуса "прототип" (для разработчика) и получает некоторое движение в сторону "продакшн" (уже для реального использования) - надписи на русском языке становятся более предпочтительными.
Как оказалось, "русифицировать" данную библиотеку оказалось относительно несложно ("относительно" - только из-за кропотливости данной работы - требуется фактически попиксельно отрисовать каждый недостающий символ).
Результат русификации можно увидеть на следующем изображении (фотография с экрана TFT):

Дополнительным результатом работы по русификации стал еще один дополнительный шрифт (SmallSymbolFont), содержащий дополнительный набор символов.
Собственно теперь расскажем, как это делается (и чуть забегая вперед - предоставим инструмент для самостоятельной корректуры написания букв и создания новых служебных символов).
Для того, чтобы сэкономить драгоценную память микроконтроллера, будем добавлять в шрифт только недостающие символы (к примеру, кириллическую букву "А" заново создавать не будем, поскольку она выглядит абсолютно идентично латинской "А").
Шрифт SmallFont описан в файле DefaultFonts.c внутри папки \libraries\UTFT - именно этот файл мы и откроем для редактирования.
В начале файла находится конструкция, которая начинается следующим образом:
fontdatatype SmallFont[1144] PROGMEM={0x08,0x0C,0x20,0x5F,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, // <Space>0x00,0x00,0x20,0x20,0x20,0x20,0x20,0x20,0x00,0x20,0x00,0x00, // !0x00,0x28,0x50,0x50,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, // "0x00,0x00,0x28,0x28,0xFC,0x28,0x50,0xFC,0x50,0x50,0x00,0x00, // #
- 0x08 - ширина знакоместа (8 точек)
- 0x0C - высота знакоместа (12 точек)
- 0x20 - "смещение" (32)
- 0x5F - количество символов в шрифте (95)
Дальше идут данные, которыми закодировано написание каждого из символов (12 байт на символ).
1 байт = 8 бит, что позволяет закодировать как раз "строчку" в составе знакоместа.
Параметр "смещение" становится понятен, если посмотреть на таблицу ASCII-кодов (к примеру, символ "пробел" имеет код 32).
В общем-то, то, что написано выше, дает полное представление о том, что мы будем делать:
- Необходимо подготовить информацию по начертанию всех недостающих символов (12 байт на каждый недостающий символ).
- Добавить полученную информацию в массив данных SmallFont.
- Скорректировать размер массива.
- Скорректировать количество символов в шрифте (4 байт в массиве).
Все остальные данные мы оставляем как есть (поскольку не изменяем их).
План работ понятен. Приступим к подготовке начертаний недостающих букв.
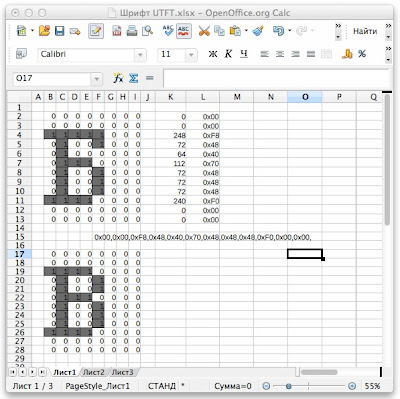
К примеру, буква "Б":
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 0 0 0 0 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 1 0 0 1 0 0 0 0 1 0 0 1 0 0 0 0 1 0 0 1 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Соответственно, выше мы видим "знакоместо", размером 8х12 и "единичками" мы указываем те пикселы, которые формируют начертание символа.
Дальше каждую строчку с "единичками" и "нулями" нужно закодировать соответствующим значением байта в шестнадцатеричной записи. К примеру, третья строчка:
B11111000 = 0xF8В левой части видны биты (нули или единички), в первой же части - то же самое, но в шестнадцатеричной системе исчисления. Для такого преобразования можно воспользоваться программой "Калькулятор", которая входит в состав любой современной операционной системы (только необходимо переключить на вид "Для программиста").
Безусловно, это все можно делать ровно по той схеме, что описано, но это как-то совершенно не интересно - работа абсолютно рутинная и требует много "ручных" действий.
Чтобы как-то эту ситуацию улучшить, воспользуемся замечательным инструментом: Microsoft Excel (или бесплатным аналогом из OpenOffice).
Автоматизируем следующее:
- Создадим правило для "условного форматирования" (чтобы фон ячейки менялся в зависимости от значения внутри ячейки) - тогда символ будет более явно виден.
- Произведем вычисление и преобразование бит в байт (в шестнадцатеричном представлении).
- Создадим строку из байтов, которая полностью описывает начертание символа (достаточно ее скопировать и вставить ее в массив SmallFont).
Получается следующее:
Внизу приведено начертание "оригинальной" буквы "В" - чтобы понимать, как распределено "пространство" в знакоместе (как организуется отступ, где находится базовая линия шрифта и т.п.).
Теперь достаточно (в верхней части файла) в пространстве знакоместа ставить "нолики" и "единички" (при этом символ автоматически "подкрашивается", что позволяет оценить то, как он будет выглядеть) и сразу же формируется строка, описывающая начертание.
Файл для MS Excel (совместим с OpenOffice) находится в архиве вместе с уже готовым файлом шрифта для библиотеки UTFT, ссылка на который находится в конце статьи.
Собственно, таким образом и формируется информация о начертании недостающих кириллических символов.
После того, как готов массив, описывающий написание каждого символа в шрифте, не забудьте скорректировать длину массива и количество символов в шрифте (см. выше).
Теперь надо сказать несколько слов о том, как пользоваться созданным шрифтом.
Если открыть файл DefaultFonts.c (на скриншоте ниже уже скорректированный файл с русифицированным шрифтом) в текстовом редакторе можно увидеть примерно следующее:
В строчках закодировано то, как будет выглядеть соответствующий символ (текущий символ отображается в конце строки в начале комментария, за ним указан десятичный и шестнадцатеричный код символа).
К примеру, для символа "б" это 150 и 0x96 (см. выделение на изображении выше).
Для печати текстов с помощью библиотеки UTFT используется следующая функция:
myGLCD.print(String, x, y);
Где String - строка, которую необходимо вывести, x и y - координаты, где необходимо вывести строку.
Теперь (для русского языка) необходимо сформировать правильную строку.
К сожалению, написать что-то типа myGLCD.print("Пишем по-русски", 0, 0); не получится (для этого требуется создать полноценный шрифт в кодировке UTF-8 (именно в ней работает IDE Arduino), но это непозволительная роскошь (из-за того, что полноценный шрифт будет занимать слишком много памяти).
Чтобы все-таки выводить кириллические надписи, требуется немного "схитрить".
Поясним это на примере слова "вода": в этом слове два символа - кириллические ("в" и "д") и два символа - латинские ("o" и "a"). Соответственно, для вывода результирующей строки мы воспользуемся следующей конструкцией:
myGLCD.print("\x97""o""\x99""a", x, y);Мы оставили латинские символы без изменения, а вместо кириллических символов сделали указание на их шестнадцатеричный код.
Бонус
В процессе работы над основным кириллическим шрифтом появилась мысль, что можно было бы создать еще несколько различных символов, с помощью которых можно было бы отображать уровень заряда батареи, уровень сигнала и т.п.
В шрифт SmallFont добавлять эти дополнительные символы посчитал нецелесообразным (они нужны не для всех случаев, а при использовании шрифта SmallFonts - просто занимали бы драгоценную память).
Все дополнительные символы были выделены в отдельный шрифт SmallSymbolFont и теперь, если они необходимы в вашем проекте, вы можете просто подключить этот шрифт (в дополнение к тем, что используются в скетче).
Например, чтобы вывести символ "батарейка 75%", нужна конструкция типа:
В примере выше мы используем десятичное представление кода необходимого символа.myGLCD.setFont(SmallSymbolFont);myGLCD.print(String(char(33)), 0, 0);
Тестовый скетч выводит все символы двух шрифтов, которые упоминаются в этом посте: SmallFont и SmallSymbolFont:

На этом первая часть русификации библиотеки завершена.
Все файлы (Excel, DefaultFonts.c и тестовый скетч, который выводит все символы шрифтов SmallFont и SmallSymbolFont) находятся в архиве по следующей ссылке.С помощью информации из данного поста и excel-файла вы можете самостоятельно скорректировать написание любых символов или создать собственные уникальные символы и пиктограммы.
Следите за обновлениями, продолжение следует...
Добрый день! Не имели дело с TFT 5"? TFT01_50 они в библиотеке называются, никак не могу завести их :(
ОтветитьУдалитьЭтот комментарий был удален автором.
ОтветитьУдалитьДобрый день, хотелось бы поинтересоваться.
ОтветитьУдалитьЯ сделал недостающий BigFont как описано в статье, но он не отображается, судя по тому как указывается длинна массива и количество символов, ошибки в моей работе нет, но я могу ошибаться... Не могли бы вы взглянуть на файл? Адрес ссылки http://files.mail.ru/F4F1A441DE3A4D34A9B25E60CA141364
Я так и не смог понять как получили для символа "б" это значение 150 и 0x96! Пожалуйста объясните подробно. Спасибо
ОтветитьУдалитьМихаил, откройте файл DefaultFonts.c из архива - там все эти значения уже прописаны. Ничего определять не надо - достаточно просто посмотреть.
ОтветитьУдалитьА я пошёл немного другим путём. Вместо отрисовки шрифтов по-новому, я просто извлёк готовые шрифты из windows fon файлов ( в кодировке 866 размерами 8x8 и 16x16). Из них сделал два шрифта (small и big fonts ) на 255 символов . Достоинства - появились символы псевдографики и прочие спец-символы к наборам латинского и русского шрифта. Если интересует - могу выложить получившийся файл .
ОтветитьУдалитьКонечно интересно - выкладывайте (желательно с описанием, как использовать).
ОтветитьУдалитьСпасибо автору за проделанную работу.
ОтветитьУдалитьЭта статья вдохновила меня на написание простенькой утилиты, которая существенно облегчит жизнь разработчикам. Утилита автоматически переводит русские символы в спец. коды, формируя "готовую строку, которую arduino спокойно скушает (проверено).
Если кого заинтересует, ссылка ниже.
(Это не вирус, не реклама и т.п. Это искреннее желание помочь собрату-программисту =P )
https://drive.google.com/file/d/0Bw1KGUKiRL5cS09uc1dURW1hSlE/view
Спасибо автору за проделанную работу.
ОтветитьУдалитьЭта статья вдохновила меня на написание простенькой утилиты, которая существенно облегчит жизнь разработчикам. Утилита автоматически переводит русские символы в спец. коды, формируя "готовую строку, которую arduino спокойно скушает (проверено).
Если кого заинтересует, ссылка ниже.
(Это не вирус, не реклама и т.п. Это искреннее желание помочь собрату-программисту =P )
https://drive.google.com/file/d/0Bw1KGUKiRL5cS09uc1dURW1hSlE/view
Dr_Glum, спасибо Вам, действительно программка имеет место быть.
ОтветитьУдалитьС Вашего разрешения, можем ли мы ее разместить на нашем сайте?
Конечно же можно! она для этого и писалась =)
УдалитьЭх, вот бы еще Dr_Glum поправил в своем замечательном приложении букву "А", а то пишет "Б" ("\x80") :)
УдалитьВ статью необходимо добавить следующую информацию:
ОтветитьУдалитьНе обязательно DefaultFonts.c изменять. Можно создать новый файл с именем, например, RusFonts.c и имя шрифта заменить на RusBigFont[]. Данный файл шрифта может находиться как в папке с библиотекой UTFT, так и в папке с самим файлом .ino.
Далее в программе декларируем шрифт:
extern uint8_t RusBigFont[];
Устанавливаем на использование:
myGLCD.setFont(RusBigFont);
И используем:
myGLCD.print("\x89""p""\x9D\x97""e""\xA4", 100, 50); //Выводим на экран слово "Привет"
Вкинул всё это дело в папку UTFT и оно постоянно ошибками ругается.
УдалитьВставил все файлы в папку UTFT и теперь IDE ругается ошибками.
УдалитьВ файле DefaultFonts.c замените третью строрку "#define fontdatatype uint8_t" на "#define fontdatatype const uint8_t"
УдалитьСкажите, в большом шрифте очень большое расстояние между буквами. Если взять ширину не 16 точек, а 12, то шрифт можно кодировать не парами по два байта, а одним трех-байтным словом. Например, не 0x1F,0xF0, а 0x7FC, соответственно, в заголовке в строке размером указать 0x0C,0x10,0x20,0x8F... Тогда и размер массива будет меньше и буквы ближе друг к другу.
ОтветитьУдалитьВсе установил, но русские буквы размытые
ОтветитьУдалитьЭтот комментарий был удален автором.
ОтветитьУдалить